
The Shift-AND algorithm is similar to KMP and Z-algorithm, it inputs a pattern P and a long text T, outputs in linear time all occurrences of P in T. While KMP only maintains the longest prefix of P that is also a suffix of the examining prefix of T, Shift-AND keeps track of all prefixes of P that match any suffixes of the examining prefix of T.
Shift-And算法不仅可以处理单模匹配问题,还可以处理每个位置允许有多种字符匹配的场景,如正则(a|b|c)&(d|e)&(f|g).
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <queue>
#include <stack>
#include <algorithm>
#include <string>
#include <map>
#include <set>
#include <vector>
using namespace std;
int GetNextP(char ch, int *code, int p) {
// p << 1 表示随着文本串增加1位 有可能匹配成功前几位
// 例如:before能匹配前2位与前4位 那么after可能 匹配前3位与前5位
// |1 表示随着文本串增加1位 是有可能 匹配成功前1位(第1位)的
// 例如:此时文本串可能 匹配模式串的前1位、前3位、前5位
// 即假设:文本串能匹配模式串的前1位、前3位、前5位
// &code[ch] 用来确认‘假设‘的正确性
// 例如:看ch这个字符是否在模式串的第1位、第3位、第5位出现过,
// 将ch在模式串中出现过的位,p对应位 置为1,没出现过的位 p对应位 置为0
return (p << 1 | 1) & code[ch];
}
/**
* @brief Shift-And 时间复杂度O(n)
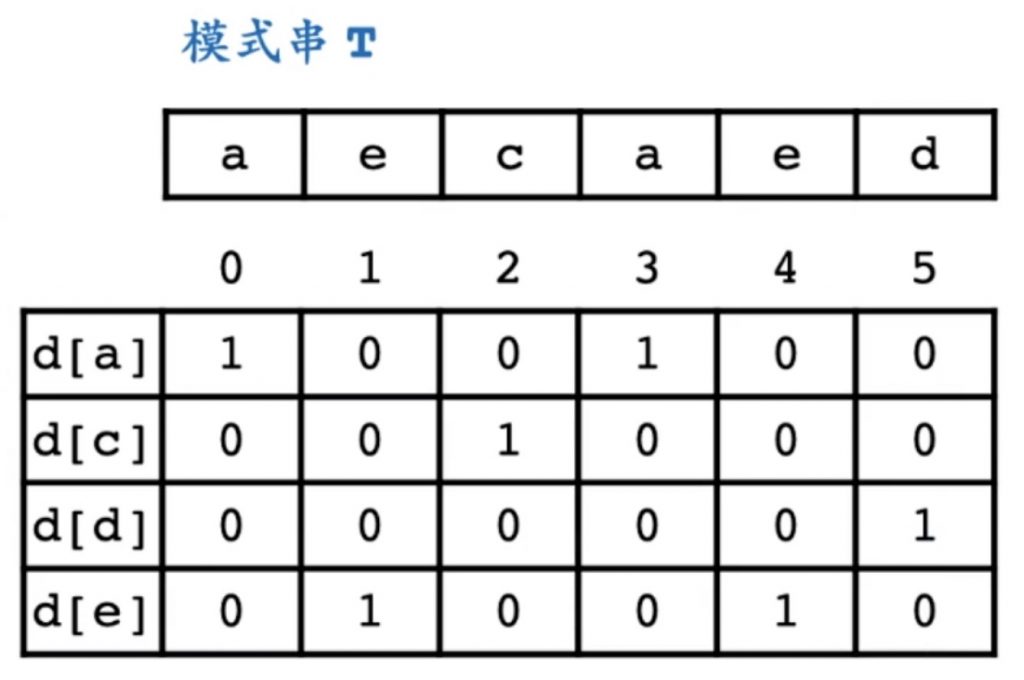
* 将模式串处理成另外一种信息格式code[](兼容性特别强) code[i]使用二进制表示pattern[n]可以出现在第几位
* 适用于流数据处理 比kmp算法更高效
* 适合处理每个位置可以有多种字符匹配的场景 如这种形式的正则表达式模式串:(a|c|d)&e&(a|b|c)&(d|f)
* @param text
* @param pattern
* @return int :pattern在text中匹配成功的起始位置
*/
int shift_and(const char *text, const char *pattern) {
int code[256] = {0};
int n = 0;
// code: int数组 记录模式串中每种字符 都在模式串的第几位出现过
// 二进制的第n位为1 代表pattern[n]在pattern的第n位出现过
for (n = 0; pattern[n]; ++n) code[pattern[n]] |= (1 << n);
// P:表示截止文本串当前索引位置i为止 能够匹配成功模式串的前几位
// 二进制的第n位值为1 代表可以匹配成功模式串的前n位
int p = 0;
for (int i = 0; text[i]; i++) {
p = GetNextP(text[i], code, p); // 完美诠释了自动机的思想
// p的第n-1位为1,表示整个模式串匹配到了
if (p & (1 << (n - 1))) return i - n + 1;
}
return -1;
}
#define TEST(func, s1, s2) { \ printf("%s(\"%s\", \"%s\") = %d\n", #func, s1, s2, func(s1, s2)); \ }
int main() {
char s1[100], s2[100];
while (cin >> s1 >> s2) {
TEST(shift_and, s1, s2);
}
return 0;
}