
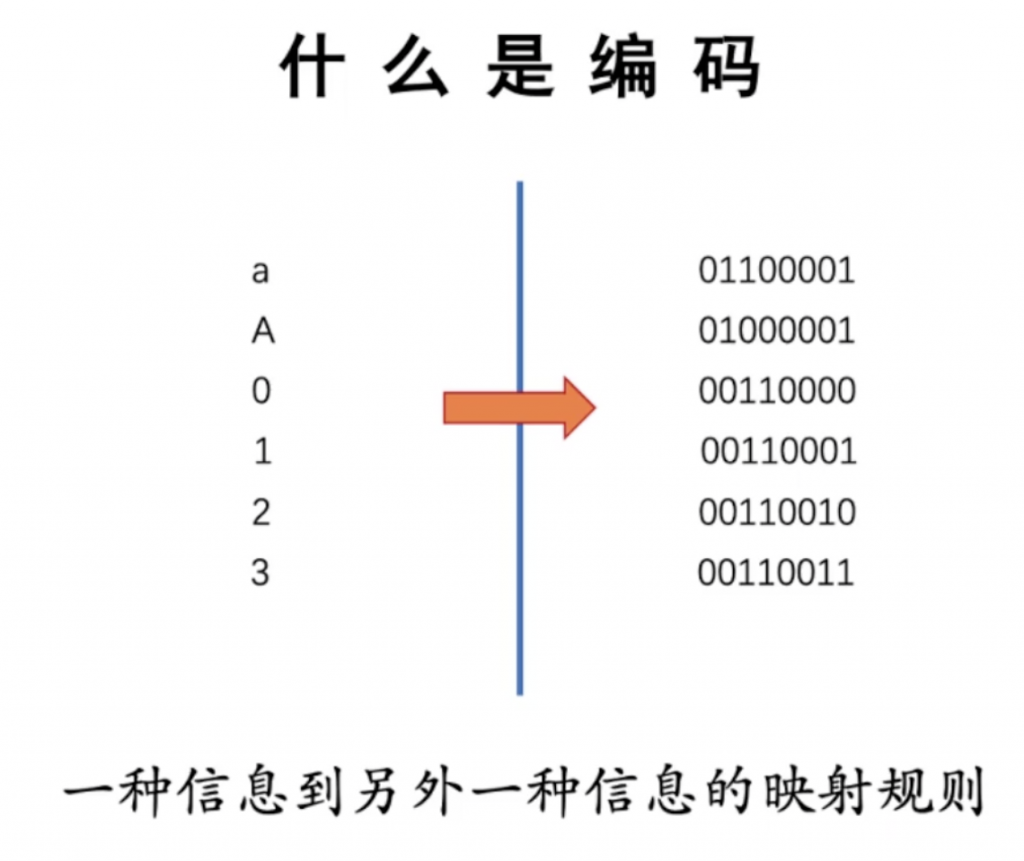
信息是如何存储的?
任何信息,在现代计算机中,都是用二进制形式(0/1)存储的。
什么是编码?
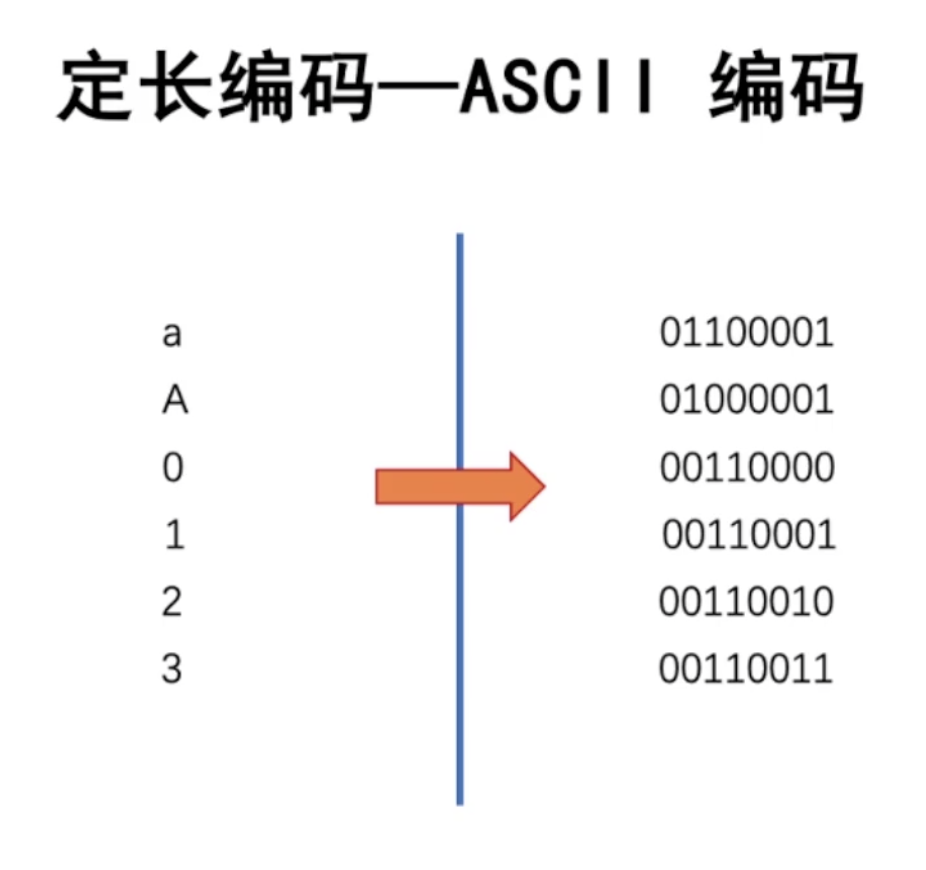
定长编码
字符的编码长度相同。
优点:容易设计。
缺点:占用空间多。
ASCII编码:每个字符占1个字节(8位)。
变长编码
编码算法是变长算法。
变长编码算法,可能输出一套长度相同的编码规则。
变长编码:从算法角度是变长的。
有效的变长编码:
- 字符的编码,不能是其他字符编码的前缀。
- 如果把编码看成二叉树上的路径,所有字符都落在叶子节点上。
注:不符合上述规则的变长编码,也是变长编码,只不过无效。所以如何设计变长编码很重要。
优点:提高信息的传输效率。
哈弗曼编码
哈弗曼编码是最优的变长编码。
生成过程:
- 统计字符的出现频率
- 建树:每次取出现频率最低的两个节点,合并成子树(新节点)
- 依次提取每个字符的编码
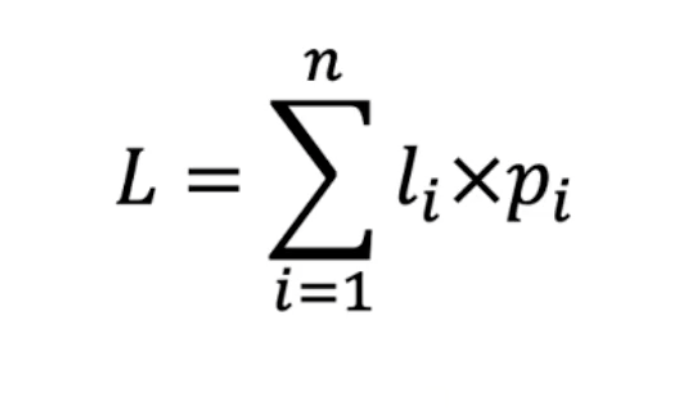
哈弗曼代码示例:
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <queue>
#include <stack>
#include <algorithm>
#include <string>
#include <map>
#include <set>
#include <vector>
using namespace std;
struct node {
node(int freq = 0, node *lchild = nullptr, node *rchild = nullptr)
: freq(freq), ch(0), lchild(lchild), rchild(rchild) {}
node(int freq = 0, char ch = 0)
: freq(freq), ch(ch), lchild(nullptr), rchild(nullptr) {}
char ch;
int freq;
node *lchild, *rchild;
};
// 排序规则
struct CMP {
bool operator()(const node *a, const node *b) const {
return a->freq < b->freq;
}
};
// 提取编码结果
// root 当前节点
// prefix 前缀编码
// code 编码结果的存储容器
void extract_code(node *root, string prefix, vector<string> &code) {
if (root->ch != 0) {
code[root->ch] = prefix;
return ;
}
extract_code(root->lchild, prefix + '0', code);
extract_code(root->rchild, prefix + '1', code);
return ;
}
int main() {
// n 字符的种类数量
// ch 字符值
// freq 字符出现频率
int n, freq, freq_arr[128];
char ch;
cin >> n;
// s 小顶堆 每次可以取出freq最低的ch
multiset<node *, CMP> s;
// 数据录入
for (int i = 0; i < n; i++) {
cin >> ch >> freq;
freq_arr[ch] = freq;
// 建树-节点插入
s.insert(new node(freq, ch));
}
// 建树-节点链接
while (s.size() > 1) {
node *a = *(s.begin()); s.erase(s.begin());
node *b = *(s.begin()); s.erase(s.begin());
s.insert(new node(a->freq + b->freq, a, b));
}
// root 树的根节点
node *root = *(s.begin());
// code 结果数组
vector<string> code(128);
extract_code(root, "", code);
for (int i = 0; i < 128; i++) {
if (code[i] == "") continue;
printf("【字符:%c】【出现频率:%5d】【编码:%s】\n", i, freq_arr[i], code[i].c_str());
}
return 0;
}
// g++ ./halfman.cpp
// ./a.out < input
