
名称:“字典树”,又称“单词查找树”,是一种树形结构,是一种哈希树的变种。
作用:1. 单词查找;2. 字符串排序。
性质:1. 根节点不包含字符,除根节点外每一个节点都只包含一个字符; 2. 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串; 3. 每个节点的所有子节点包含的字符都不相同。
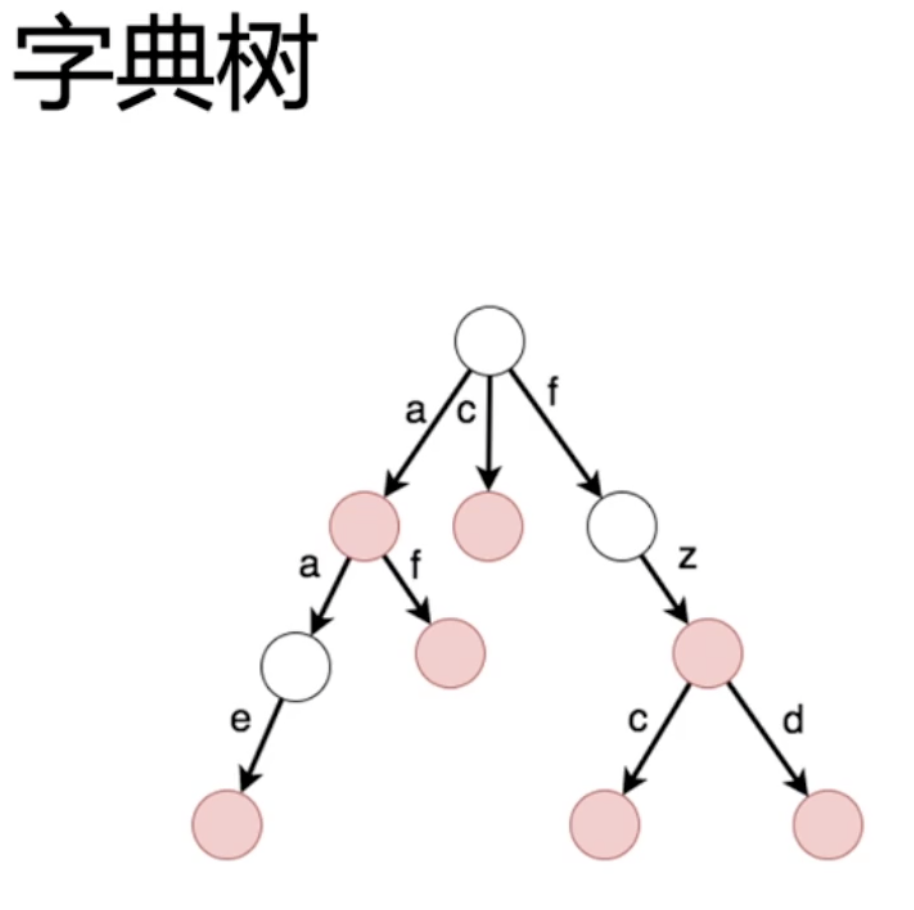
Q:按照字典序写出上面字典树中的所有单词【提示:深度优先遍历】
- a
- aae
- af
- c
- fz
- fzc
- fzd
字典树的基本代码实现(指针):
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <queue>
#include <stack>
#include <algorithm>
#include <string>
#include <map>
#include <set>
#include <vector>
using namespace std;
#define BASE 26
// 定义节点
class node {
public:
node() {
flag = false;
for (int i = 0; i < BASE; i++) next[i] = nullptr;
}
~node() {}
bool flag; // 标识:节点是否独立成词
node *next[26]; // 定义节点的边
};
// 定义字典树
class Trie
{
private:
node *root; //根节点
public:
Trie() {
root = new node();
};
// 插入
bool insert(string word) {
node *p = root;
for (auto x : word) {
int ind = x - 'a';
if (p->next[ind] == nullptr) p->next[ind] = new node();
p = p->next[ind];
}
if (p->flag) return false;
p->flag = true;
return true; // 代表 是否第一次插入
}
// 查找
bool search(string word) {
node *p = root;
for (auto x : word) {
int ind = x - 'a';
p = p->next[ind];
if (p == nullptr) return false;
}
return p->flag;
}
// 排序【dfs遍历】
void output() {
__output(root, "");
return;
}
static void __output(node *root, string prefix) {
if (root == nullptr) return;
if (root->flag) cout << "find: " << prefix << endl;
for (int i = 0; i < BASE; i++) {
__output(root->next[i], prefix + char(i + 'a'));
}
return;
}
static void clearTrie(node *root) {
if (root == nullptr) return;
for (int i = 0; i < BASE; i++) clearTrie(root->next[i]);
delete root;
return;
}
~Trie() {
clearTrie(root);
}
};
// 测试字典树的插入与查找
int main_test0() {
Trie t;
int op;
string s;
while (cin >> op >> s)
{
switch (op)
{
case 1:
t.insert(s);
break;
case 2:
cout << "search word = " << s << ", result :" << t.search(s) << endl;
default:
break;
}
}
return 0;
}
// 测试字典树对字符串的排序
int main_test1() {
int n; //定义容量
cin >> n;
string s;
Trie t;
for (int i = 0; i < n; i++) {
cin >> s;
t.insert(s);
}
t.output();
return 0;
}字典树的竞赛代码实现(数组):
// 字典树的竞赛写法
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <queue>
#include <stack>
#include <algorithm>
#include <string>
#include <map>
#include <set>
#include <vector>
using namespace std;
#define BASE 26
class node {
public:
int flag; // 节点是否独立成词
int next[BASE]; // 边的信息 每一个节点在数组中的下标
void clear() {// 初始化当前节点
flag = 0;
for (int i = 0; i < BASE; i++) {
next[i] = 0; // Trie的下标为0 代表没有挂载节点
}
}
} trie[10000]; // 用数组的物理结构书写trie的逻辑结构
// cnt 维护:当前能够使用的 下一个未使用节点的编号
// root 维护:根节点的编号
int cnt, root;
// 初始化Trie
void clearTrie() {
cnt = 2, root = 1;
trie[root].clear();
return;
}
// 创建节点
int getNewNode() {
trie[cnt].clear();
return cnt++;
}
// 插入
void insert(string s) {
int p = root; // p:维护的是trie中节点的下标
for (auto x : s) {
int ind = x - 'a';
if (trie[p].next[ind] == 0) trie[p].next[ind] = getNewNode();
p = trie[p].next[ind];
}
trie[p].flag = 1;
return;
}
// 查找
bool search(string s) {
int p = root; // p:维护的是trie中节点的下标
for (auto x : s) {
int ind = x - 'a';
p = trie[p].next[ind];
if (p == 0) return 0;
}
return trie[p].flag;
}
// 测试
int main() {
cout << "competition version" << endl;
clearTrie();
int op;
string s;
while (cin >> op >> s)
{
switch (op)
{
case 1:
insert(s);
break;
case 2:
cout << "search word = " << s << ", result :" << search(s) << endl;
default:
break;
}
}
return 0;
}双数组字典树(Double-Array-Trie)
双数组Trie(Double-ArrayTrie)是trie树的一个简单而有效的实现,由两个整数数组构成,一个是base[],另一个是check[]。
base[] 的index,用于表示当前节点的下标。
base[] 记录的是基础值,生成基础值的过程中,需要保证基础值不发生冲突:t = base[i] + ‘s’,即base[t]是空的。
备注:s代表节点的每条边(有子节点的边),转换为的int值。
由父节点的下标i,可以推算出,其子节点的下标t。
check[] 的index,用于表示‘当前节点的子节点’的下标。
check[] 记录的是子节点对应的父节点index,可用于判断父节点在这条边上是否有子节点。
将check[t] 赋值为i (其父节点的base值):check[t] = i 。
可约定,如果check[t]记录的是负值,表示成词。
代码实现:
// 双数组字典树
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <queue>
#include <stack>
#include <algorithm>
#include <string>
#include <map>
#include <set>
#include <vector>
using namespace std;
#define BASE 26
#define MAX_CNT 1000
class node {
public:
int flag; // 节点是否独立成词
int next[BASE]; // 边的信息 每一个节点在数组中的下标
void clear() {// 初始化当前节点
flag = 0;
for (int i = 0; i < BASE; i++) {
next[i] = 0; // Trie的下标为0 代表没有挂载节点
}
}
} trie[MAX_CNT]; // 用数组的物理结构书写trie的逻辑结构
// cnt 维护:当前能够使用的 下一个未使用节点的编号
// root 维护:根节点的编号
int cnt, root;
// 初始化Trie
void clearTrie() {
cnt = 2, root = 1;
trie[root].clear();
return;
}
// 创建节点
int getNewNode() {
trie[cnt].clear();
return cnt++;
}
// 插入
void insert(string s) {
int p = root; // p:维护的是trie中节点的下标
for (auto x : s) {
int ind = x - 'a';
if (trie[p].next[ind] == 0) trie[p].next[ind] = getNewNode();
p = trie[p].next[ind];
}
trie[p].flag = 1;
return;
}
// 查找
bool search(string s) {
int p = root; // p:维护的是trie中节点的下标
for (auto x : s) {
int ind = x - 'a';
p = trie[p].next[ind];
if (p == 0) return 0;
}
return trie[p].flag;
}
// base[]: 下标为节点下标,值为节点base值
// check[]: 下标为子节点的下标,值为父节点的index
// da_root: DoubleArrayTrie的root节点下标 下标0代表base[]/check[]的初始值
int *base, *check, da_root = 1;
// 为节点生成base
int getBaseValue(int root, int *base, int *check) {
int b = 1; // 初始化base
bool flag = false; // 标识 是否找到了可用的base: check[b + i] == 0
while (!flag) {
b += 1; // base循环累加 尝试
flag = true;
for (int i = 0; i < BASE; i++) {
if (trie[root].next[i] == 0) continue; // 没有节点则跳过
// 有节点
if (check[b + i] == 0) continue; // 子节点对应的check[] index未被占用
flag = false;
break;
}
}
return b;
}
/**
* @param root: Trie根节点index
* @param da_root: DoubleArrayTrie根节点index
* @param base: base[]
* @param check: check[]
* @return max_ind:维护DoubleArrayTrie节点的最大索引
*/
int ConvertToDoubleArrayTrie(int root, int da_root, int *base, int *check) {
int max_ind = da_root;
base[da_root] = getBaseValue(root, base, check);
for (int i = 0; i < BASE; i++) {
if (trie[root].next[i] == 0) continue;
check[base[da_root] + i] = da_root; // 给root子节点进行check赋值
if (trie[trie[root].next[i]].flag) {
check[base[da_root] + i] = -da_root; // 标记 成词
}
}
for (int i = 0; i < BASE; i++) {
if (trie[root].next[i] == 0) continue;
max_ind = max(
max_ind,
ConvertToDoubleArrayTrie(trie[root].next[i], base[da_root] + i, base, check)
);
}
return max_ind;
}
bool searchDATrie(string s) {
int p = da_root;
for (auto x : s) {
int ind = x - 'a';
if (abs(check[base[p] + ind]) != p) return false;
p = base[p] + ind;
}
return check[p] < 0;
}
// 测试
int main() {
cout << "DoubleArrayTrie:" << endl;
clearTrie();
// 定义输入字符串数量
int n;
cin >> n;
// 写入普通Trie
string s;
for (int i = 0; i < n; i++) {
cin >> s;
insert(s);
}
base = new int[MAX_CNT];
check = new int[MAX_CNT];
memset(base, 0, sizeof(int) * MAX_CNT);
memset(check, 0, sizeof(int) * MAX_CNT);
int max_ind = ConvertToDoubleArrayTrie(root, da_root, base, check);
printf("trie usage : %lu byte\n", cnt * sizeof(node));
printf("double array trie usage : %lu bype\n", (max_ind + 1) * sizeof(int) * 2); // *2: base[] + check[]
while (cin >> s) {
cout << "find " << s << ", from trie : " << search(s) << endl;
cout << "find " << s << ", from da trie : " << searchDATrie(s) << endl;
}
return 0;
}